Catch the bug, walking through the stack
Published: 2016-05-03 (last updated: 2024-10-11)
BAD RECORD MAC
Roughly 2 weeks ago, Engil informed me that a TLS alert pops up in his browser sometimes when he reads this website. His browser reported that the message authentication code was wrong. From RFC 5246: This message is always fatal and should never be observed in communication between proper implementations (except when messages were corrupted in the network).
I tried hard, but could not reproduce, but was very worried and was eager to find the root cause (some little fear remained that it was in our TLS stack). I setup this website with some TLS-level tracing (extending the code from our TLS handshake server). We tried to reproduce the issue with traces and packet captures (both on client and server side) in place from our computer labs office with no success. Later, Engil tried from his home and after 45MB of wire data, ran into this issue. Finally, evidence! Isolating the TCP flow with the alert resulted in just about 200KB of packet capture data (TLS ASCII trace around 650KB).
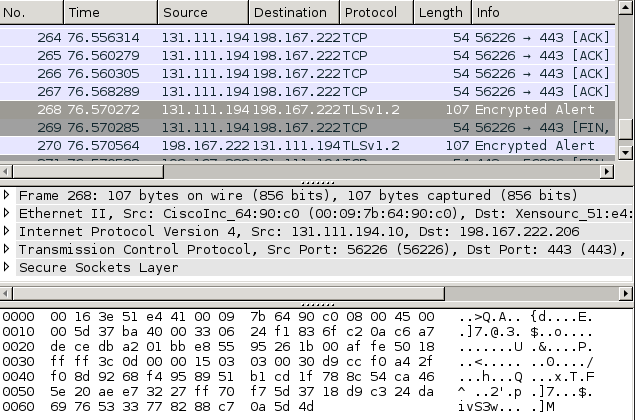
What is happening on the wire? After some data is successfully transferred, at some point the client sends an encrypted alert (see above). The TLS session used a RSA key exchange and I could decrypt the TLS stream with Wireshark, which revealed that the alert was indeed a bad record MAC. Wireshark's "follow SSL stream" showed all client requests, but not all server responses. The TLS level trace from the server showed properly encrypted data. I tried to spot the TCP payload which caused the bad record MAC, starting from the alert in the client capture (the offending TCP frame should be closely before the alert).
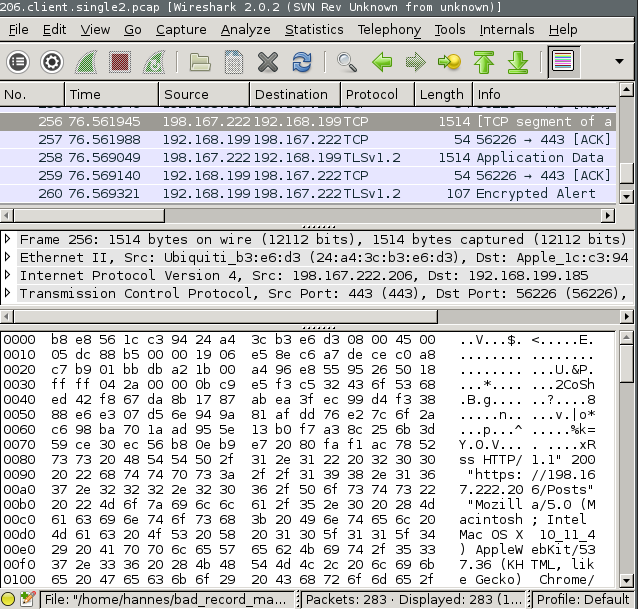
There is plaintext data which looks like a HTTP request in the TCP frame sent by the server to the client? WTF? This should never happen! The same TCP frame on the server side looked even more strange: it had an invalid checksum.
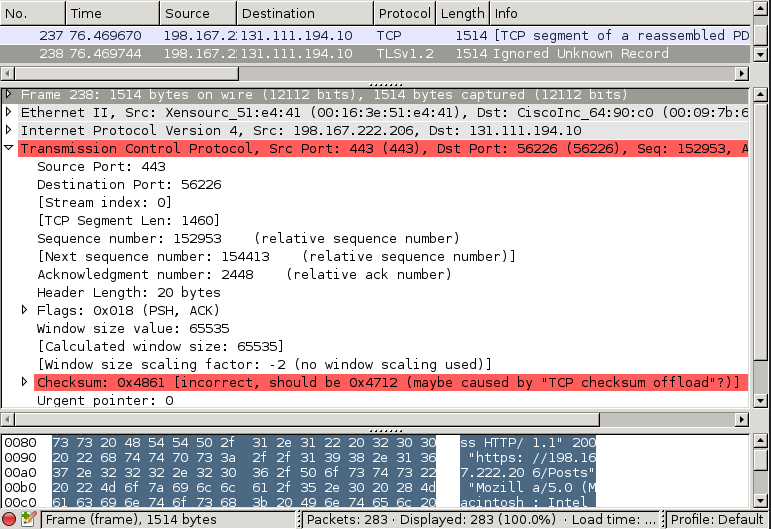
What do we have so far? We spotted some plaintext data in a TCP frame which is part of a TLS session. The TCP checksum is invalid.
This at least explains why we were not able to reproduce from our office: usually, TCP frames with invalid checksums are dropped by the receiving TCP stack, and the sender will retransmit TCP frames which have not been acknowledged by the recipient. However, this mechanism only works if the checksums haven't been changed by a well-meaning middleman to be correct! Our traces are from a client behind a router doing network address translation, which has to recompute the TCP checksum because it modifies destination IP address and port. It seems like this specific router does not validate the TCP checksum before recomputing it, so it replaced the invalid TCP checksum with a valid one.
Next steps are: what did the TLS layer intended to send? Why is there a TCP frame with an invalid checksum emitted?
Looking into the TLS trace, the TCP payload in question should have started with the following data:
0000 0B C9 E5 F3 C5 32 43 6F 53 68 ED 42 F8 67 DA 8B .....2Co Sh.B.g..
0010 17 87 AB EA 3F EC 99 D4 F3 38 88 E6 E3 07 D5 6E ....?... .8.....n
0020 94 9A 81 AF DD 76 E2 7C 6F 2A C6 98 BA 70 1A AD .....v.| o*...p..
0030 95 5E 13 B0 F7 A3 8C 25 6B 3D 59 CE 30 EC 56 B8 .^.....% k=Y.0.V.
0040 0E B9 E7 20 80 FA F1 AC 78 52 66 1E F1 F8 CC 0D ........ xRf.....
0050 6C CD F0 0B E4 AD DA BA 40 55 D7 40 7C 56 32 EE l....... @U.@|V2.
0060 9D 0B A8 DE 0D 1B 0A 1F 45 F1 A8 69 3A C3 4B 47 ........ E..i:.KG
0070 45 6D 7F A6 1D B7 0F 43 C4 D0 8C CF 52 77 9F 06 Em.....C ....Rw..
0080 59 31 E0 9D B2 B5 34 BD A4 4B 3F 02 2E 56 B9 A9 Y1....4. .K?..V..
0090 95 38 FD AD 4A D6 35 E4 66 86 6E 03 AF 2C C9 00 .8..J.5. f.n..,..
The ethernet, IP, and TCP headers are in total 54 bytes, thus we have to compare starting at 0x0036 in the screenshot above. The first 74 bytes (till 0x007F in the screenshot, 0x0049 in the text dump) are very much the same, but then they diverge (for another 700 bytes).
I manually computed the TCP checksum using the TCP/IP payload from the TLS trace, and it matches the one reported as invalid. Thus, a big relief: both the TLS and the TCP/IP stack have used the correct data. Our memory disclosure issue must be after the TCP checksum is computed. After this:
- the IP frame header is filled
- the mac addresses are put into the ethernet frame
- the frame is then passed to mirage-net-xen for sending via the Xen hypervisor.
As mentioned earlier I'm still using mirage-net-xen release 1.4.1.
Communication with the Xen hypervisor is done via shared memory. The memory is allocated by mirage-net-xen, which then grants access to the hypervisor using Xen grant tables. The TX protocol is implemented here in mirage-net-xen, which includes allocation of a ring buffer. The TX protocol also has implementations for writing requests and waiting for responses, both of which are identified using a 16bit integer. When a response has arrived from the hypervisor, the respective page is returned into the pool of shared pages, to be reused by the next packet to be transmitted.
Instead of a whole page (4096 byte) per request/response, each page is split into two blocks (since the most common MTU for ethernet is 1500 bytes). The identifier in use is the grant reference, which might be unique per page, but not per block.
Thus, when two blocks are requested to be sent, the first polled response will immediately release both into the list of free blocks. When another packet is sent, the block still waiting to be sent in the ringbuffer can be reused. This leads to corrupt data being sent.
The fix was already done back in December to the master branch of mirage-net-xen, and has now been backported to the 1.4 branch. In addition, a patch to avoid collisions on the receiving side has been applied to both branches (and released in versions 1.4.2 resp. 1.6.1).
What can we learn from this? Read the interface documentation (if there is any), and make sure unique identifiers are really unique. Think about the lifecycle of pieces of memory. Investigation of high level bugs pays off, you might find some subtle error on a different layer. There is no perfect security, and code only gets better if more people read and understand it.
The issue was in mirage-net-xen since its initial release, but only occured under load, and thanks to reliable protocols, was silently discarded (an invalid TCP checksum leads to a dropped frame and retransmission of its payload).
We have seen plain data in a TLS encrypted stream. The plain data was intended to be sent to the dom0 for logging access to the webserver. The same code is used in our Piñata, thus it could have been yours (although I tried hard and couldn't get the Piñata to leak data).
Certainly, interfacing the outside world is complex. The mirage-block-xen library uses a similar protocol to access block devices. From a brief look, that library seems to be safe (using 64bit identifiers).
I'm interested in feedback, either via twitter or via eMail.
Other updates in the MirageOS ecosystem
- Canopy uses a map instead of a hashtable, tags now contains a list of tags (PR here), both thanks to voila! I also use the new CSS from Engil
- There is a CVE for OCaml <=4.03
- Mirage 2.9.0 was released, which integrates support of the logs library (now already used in mirage-net-xen and mirage-tcpip)
- This blog post has an accompanied MirageOS security advisory
- cfcs documented some basic unikernels